CUDAでGPUプログラミング
2024.06.09
■目的
・Tensorflow や Pytorch で間接的にしかGPUを使っていなかったので、もっと根っこの部分を知って GPUについての知見を深めたい。
・cuda でサンプルプログラムを書いてみる。
■実験環境
・OS・・Windows10 Pro
・CPU・・Intel(R) Core(TM) i7-8700 CPU @ 3.20GHz 3.19 GHz
・GPU・・RTX2070
■準備
・CUDA Toookit 12.5 をダウンロードしインストール。
・nvcc にPATHを通す。nvcc が cuda のコンパイラ。
■実験内容
・1~nまでの合計値を出すプログラムで、CPUとGPUでの違いを見る。
・nvcc でコンパイルし、実行ファイルを実行する。
■結果
| 1億まで合計する所要時間 合計値:5000000050000000 |
10億まで合計する所要時間 合計値:500000000500000000 |
|
|---|---|---|
| CPU | 0.04 秒 | 0.4秒 |
| GPU | 0.00001秒 | 0.00003秒 |
※100億はGPUのメモリ不足で実行できず。
■所感
・cudaはほぼC言語だった。
・実行順序を問わないお題であればGPUのメリットが活かせる。ものによっては1000分の1くらいの時間で済む。
・GPUのグリッド、ブロック、スレッドといった基本構造を知ることができた。
・スレッドを使った並列処理がどれくらい強力であるか実感できた。
・pyCUDAを使えば、pythonからcudaを実行できるので選択肢が広がった。cudaを知れて、世界が広がった気がする。
・複数マシンかつ複数GPU環境での分散並列処理も実現可能。
Tensorflowなら「MultiWorkerMirroredStrategy」
Pytorchなら「DistributedDataParallel」
が用意されている。
■追加実験
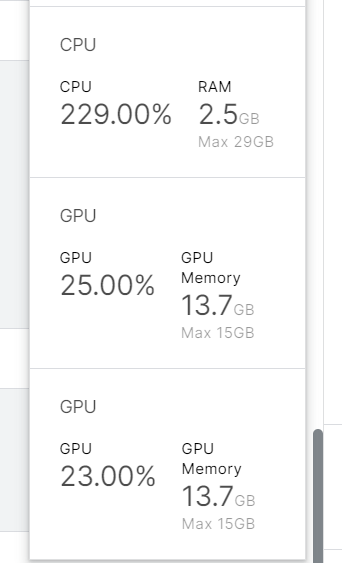
・複数GPU環境が用意できなかったのでKaggle環境(GPU T4 * 2)でTensorflowの「MirroredStrategy」を試してみた。
使用率から複数GPUで分散処理ができていそう。
最新記事
- 自社サービス「クイズファミリー」の開発
- ランニングフォームの数値化
- AIに小説を書いてもらう
- AWS Managed Blockchain(AMB)の使用・・・
- APIサービスをどう作るか
- C++による組込みプログラミング
- CUDAでGPUプログラミング
- BERTでチャットボット
- 脆弱性チェックツール
- Flutterでデスクトップアプリ
- MMPoseを使って姿勢推定(骨格検知)
- Laravel Livewire3を使ってみる
- Lineミニアプリ
- RustとPHPのパフォーマンス比較
- ボクシングをモーションキャプチャー
- Virtualbox上のUbuntuにDocker環境を作れ・・・
- AWSでのIPv6対応
- AWSのRDSでブルー/グリーンデプロイ
- 20年ぶりにCOBOL
- フィッシングメールのソースを見る